Tl;Dr
- GCP の構成管理ツール(Infrastructure as Code)として Pulumi を導入してみた。
- TypeScript でコード補完などの機能にたよりながら記述できるのは快適だった。
- マルチステージで適用する必要があったが、コードで記述できるゆえにシンプルに対処できた。
- Shell Script で1コマンドでインフラを構築できるようにした。
- Pulumi はいいぞ。
まえがき
以前の記事で書いたように、最近 Crystal(と Ruby)でがんばるぞい bot を復活させました。
しかし、GCP の構成管理は行っておらず、GCP の管理コンソール上でポチポチしながらインフラを構築していました。
今回はプラットフォームへの依存が殆どないため、Go/GAE による3代目のがんばるぞいbot にあったような事件は起こらないだろうとしても、また何かあったら非常に面倒ではあります。例えば GCP のインフラを誤って吹き飛ばすとか・・・。
まぁ、それはさすがに無いにしても今の時代に構成管理をしていないのはどうなんよという話でもあります故、Terraform などを導入したいなぁとは思っていました。
しかし、Kubernetes などの設定ファイルの記述の面倒さを思い出すと、なかなか重い腰が上がりませんでした。
Pulumi 3.0 のリリース
そんな中、ある技術ニュースが飛び込んできました。
えぇ、思いましたよ。「また新しい構成管理ツールですかぁ・・・」と。
Pulumi というサービスは聞いたことがありませんでしたが、クラウドの構成管理といえば HashiCorp・Terraform がデファクトに決まっています。あの Vagrant だって HashiCorp 製のツールだったはずです。
しかし、少し調べてみると設定を TypeScript などのプログラミング言語で記述できるようで、それは単純な記述ミスはコンパイルエラーで検出できることを意味していました。
えぇ、思いましたよ。「これは・・・触ってみるしか無い。」と。
Pulumi って?
すでに殆ど書いてしまいましたが、クラウドサービスなどの構成管理ツールで Infrastructure as Code を実現するサービスです。
この分野に詳しい人には Terraform みたいなもの、と言ったほうが早いかもしれません。
以下の記事が分かりやすくて参考になりました。
最大の特徴・・・かどうかは分かりませんが、設定をプログラミング言語で記述できるのが大きな特徴になっています。Terraform は HCL という独自言語で記述する仕組みらしいので、これは大きな違いの一つかと思います。
執筆時点において、公式でサポートされているプログラミング言語 は以下の4つです。
- Node.js(TypeScript / JavaScript)
- Python
- .NET Core(C# / F# / …)
- Go
設定ミスをコンパイルエラーで検出できる点にメリットを見出していたので、まず Python は選択肢から除外されました(これは私が Python しか書けなかった場合でも同様でしょう)。
.NET は C# 2.0 をずっと昔に触ったくらいなのでこれも除外し、Go は記述が冗長になりそうなイメージ(単なる直感ですが)があったのでそれも除外し、結果として残った TypeScript を採用することにしました。
TypeScript による記述
一言で言うなら、非常に快適でした。
コード補完に頼って必要な API を探したり、定義にジャンプして設定値を調べたりすることができ、ドキュメントを細かく調べなくても記述できてしまう箇所が殆どでした。
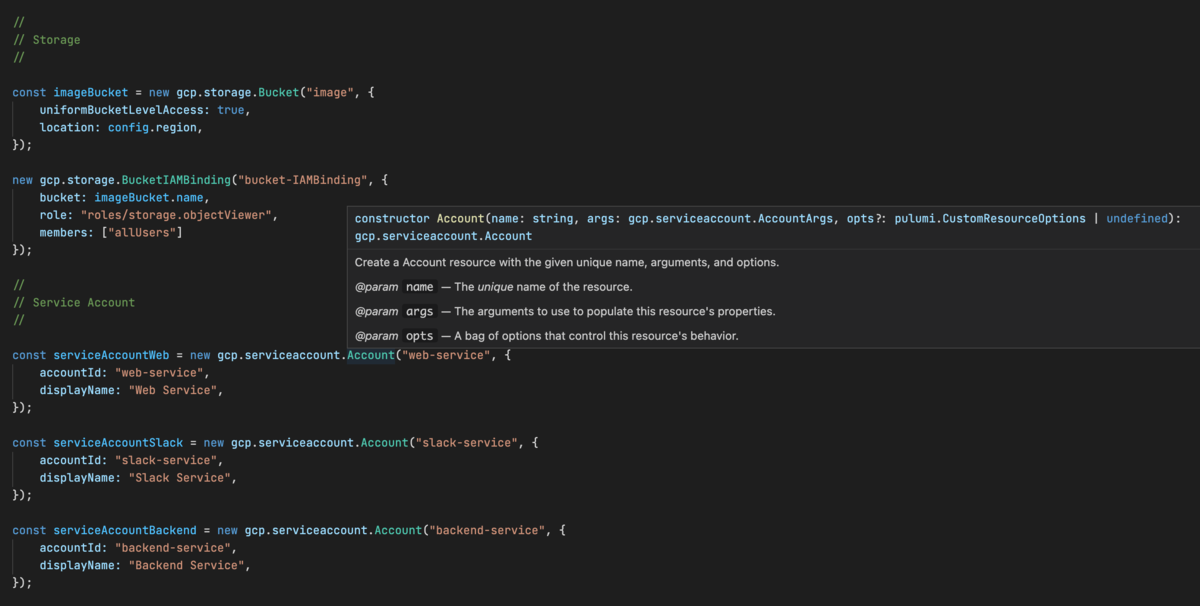
共通化したい箇所も関数を定義したり、ループで回したりするだけでよく、まさにこれこそ Infrastructure as Code だと感じました。
設定値の管理
構成する上で、デプロイ先のリージョンやサービス名など、環境によって変更したい設定値は多々ありますが、それらは pulumi config というコマンドによって管理できました。

設定した値はすべて Pulumi のサービス上で管理されるため、ローカルでファイルを管理したりバージョン管理システムにコミットしたりする必要はありません(pulumi config refresh というコマンドでローカルファイルに引っ張ってこれます)。
上のスクリーンショットで [secret] と出力されている箇所がありますが、これは暗号化して保存すると指定したもので、コンソールなどに誤って出力されないようになっています(AWS / GCP などの任意のセキュアストレージを利用することも可能なようです)。
デプロイ時の差分確認
記述した設定は pulumi up というコマンドで実際に反映できるのですが、その際にリソースの差分を確認することができるのも便利だと思いました。
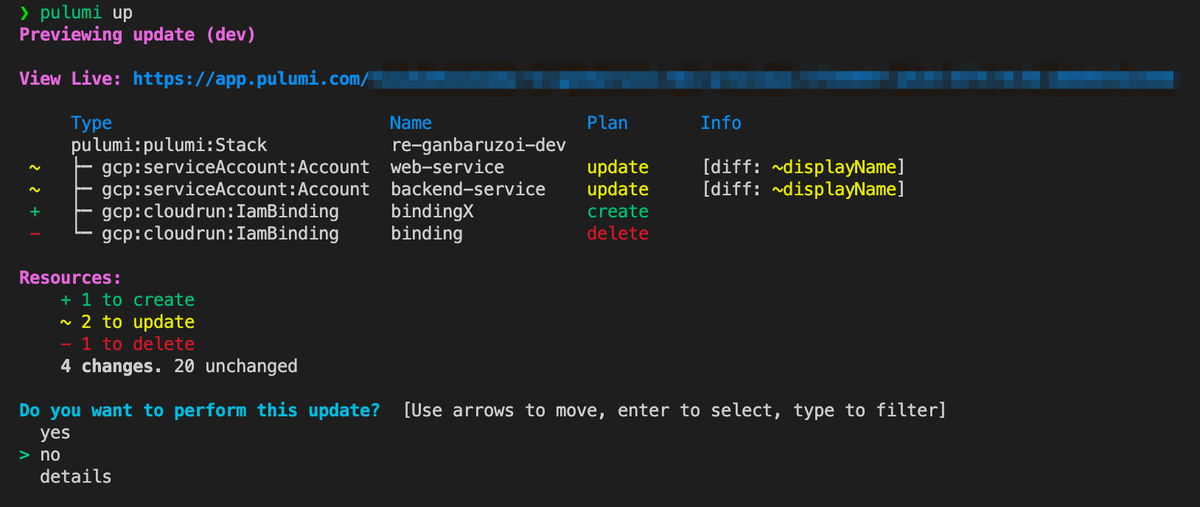
より詳細な差分は details を選択することで確認でき、記述したコードが実際にどのようなリソースに反映されるのかが分かるため、試行錯誤しながら記述を進めることができた気がします。
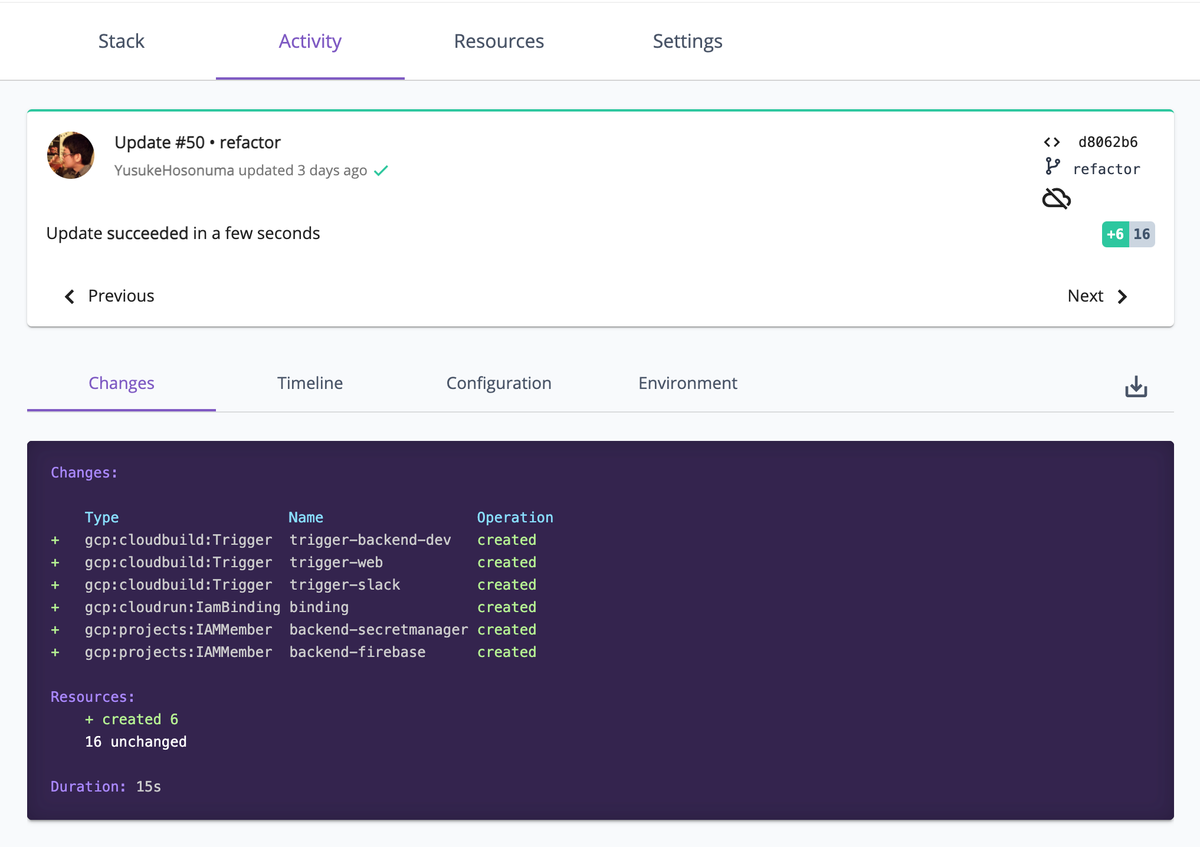
適用した内容は CI サービスのような感じで、Web 管理コンソールからも確認できるため、何か問題があったときにも原因の追跡がしやすいとだろうと思いました。
マルチステージなデプロイ
そんなこんなで少しずつ Pulumi でのリソース管理に置き換えていったのですが、1つの問題にぶつかりました。
それが、「リソース・サービスに依存関係があるため、段階的にリソースを適用していく必要がある」ということで、言い換えると一度の pulumi up では構成しきれないということでした 1。
これは以下の図を見ていただくのがわかりやすいでしょう。
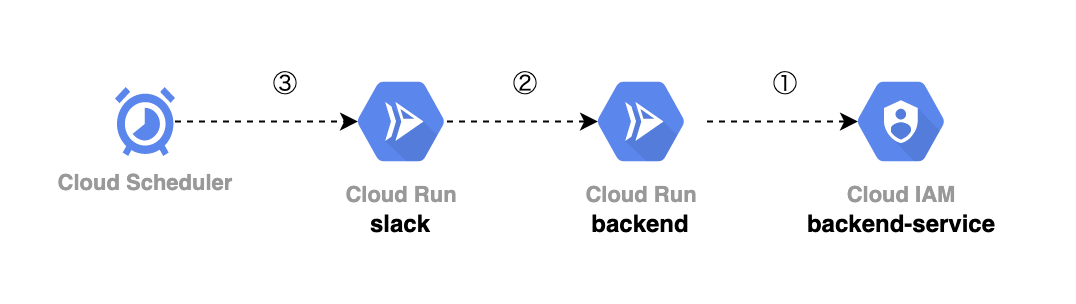
いや、あんまり分かりやすくは無かったですね、すみません(笑)
まぁ端的に言うと、リソースの構成のために「事前に起動しておかなければならない Cloud Run サービス」が存在する、というマイクロサービスゆえに必要なつなぎ込み的な問題でした(GKE、というか Kubernetes を利用するならばこのあたりを考える必要はなかったのでしょうが・・・GKE は料金が高くてですね・・・)。
この問題にどう対処するか迷いましたが、シンプルに環境変数でステージ番号を与え、それによってマルチステージビルドを実現する方法で対処しました。
これは以下の抜粋ソースを見ていただくのがわかりやすいでしょう。
const STAGE = process.env["STAGE"] == null ? 100 : Number(process.env["STAGE"]) // ⭐ STAGE:0 の構成 // // Depends: 'Backend' service was deployed. // if (STAGE >= 1) { // ⭐ STAGE:1 の構成 } // // Depends: 'Slack' service was deployed. // if (STAGE >= 2) { // ⭐ STAGE:2 の構成 }
100 というマジックナンバーから溢れ出る素人感はさておき(本当は Number.MAX てきなやつを使うべきでしょう)、環境変数 STAGE で構成するステージの番号を与え、それによってマルチステージビルドを実現しているのが読み取れるかと思います。
一度構築が完了したら、環境変数 STAGE を省略することですべてのリソースが適用される、という感じです。
あとは ShellScript を用意して、そこから pulumi up を適宜呼び出すことで、1コマンドでインフラが構築できるようになりました。
参考までにソース全文を貼っておきます。
pulumi config get や pulumi stack output で設定値や構成済みリソースの値を取得しているところが、見どころといえば見どころでしょうか。
#!/bin/bash
COMMIT_SHA=$(git rev-parse HEAD)
SERVICE_NAME_WEB=$(pulumi config get --path data.service.web)
SERVICE_NAME_SLACK=$(pulumi config get --path data.service.slack)
SERVICE_NAME_BACKEND=$(pulumi config get --path data.service.backend)
#
# Pulumi stage: 0
#
STAGE=0 pulumi up -y
_BUCKET_NAME=$(pulumi stack output imageBucketName)
#
# Deploy Backend service
#
cd ../
gcloud builds submit \
--config ./service/backend/cloudbuild.yaml \
--substitutions="COMMIT_SHA=${COMMIT_SHA},_SERVICE_NAME=${SERVICE_NAME_BACKEND},_BUCKET_NAME=${_BUCKET_NAME}"
#
# Pulumi stage: 1
#
cd ./infra
STAGE=1 pulumi up -y
#
# Deploy Web service
#
cd ../
_BACKEND_URL=$(gcloud run services describe ${SERVICE_NAME_BACKEND} --platform=managed --format=json | jq -r '.status.url')
gcloud builds submit \
--config ./service/web/cloudbuild.yaml \
--substitutions="COMMIT_SHA=${COMMIT_SHA},_SERVICE_NAME=${SERVICE_NAME_WEB},_BACKEND_URL=${_BACKEND_URL}"
#
# Deploy Slack service
#
gcloud builds submit \
--config ./service/slack/cloudbuild.yaml \
--substitutions="COMMIT_SHA=${COMMIT_SHA},_SERVICE_NAME=${SERVICE_NAME_SLACK},_BACKEND_URL=${_BACKEND_URL}"
#
# Pulumi stage: 2
#
cd ./infra
STAGE=2 pulumi up -y
現状の不満点を挙げるとするなら、Cloud Run のサービス起動に gcloud builds submit を利用している点です。
というのは、CI/CD のために Cloud Build のトリガーも構成しているので、それをプログラム上から叩ければそれだけで解決する話だったのですが、残念ながら GCP のドキュメントを読んでも、そのやり方を見つけることが出来ませんでした(絶対にあると思うのですが・・・)。
おわりに
ということで、Pulumi を導入してみた感想的な記事でした。
今回、Pulumi の導入をする際にそこまでドキュメントをしっかり読まずにわりと雰囲気で進めたのですが、マルチステージビルドの問題以外はそこまで苦労した箇所はなく、クラウド構成管理ツールとしてはかなり敷居が低いのではないかと思いました。
マルチステージビルドは・・・まぁ他にベターな方法があったかもしれませんが、こういう解決の仕方もあった的な感じの参考程度にしていただければ幸いです。
Pulumi はいいぞ。
P.S.
最近、カウボーイ・ビバップを観直しはじめているのですが、いやはやハードボイルドなアニメ作品の傑作ですな。これは。
-
疑問を感じる人もいるかもなので補足しておきますと、より正確に言うならば Cloud Run のデプロイを Pulumi でやれば問題はなかった(はず)なのですが、せっかく Cloud Build でデプロイを管理しているのに DRY に反して Pulumi で重複して記述するのはナンセンスだと感じたためです。そのためもう一つの解決策として、Cloud Build の定義から Pulumi の定義を自動生成(cloudbuild.yaml をパースすれば論理的には可能なはずです)、あるいはその逆をするというアプローチもありだったと思います。↩